Uma visão geral de Machine Learning
O artigo da wikipédia é longo demais.
O que é Machine Learning, matematicamente?
Efetivamente, machine learning é sobre entregar dados para um máquina, de forma que ela “aprenda” com esses dados e consiga fazer previsões sobre dados não antes vistos.
Mas de forma mais objetiva (que é o que interessa): no aprendizado de máquina, nós queremos descobrir qual função está por trás de um certo conjunto de dados. Por exemplo, nossos dados poderiam ser uma lista de pontos:
| 1 | 1 |
| 2 | 4 |
| 3 | 8 |
| 4 | 16 |
Nossa máquina poderia aprender então que a função por trás desses dados é $(x, x^2)$.
É importante ressaltar que essa escolha de função é “subjetiva”: existem infinitas funções que produziriam os mesmos dados que foram entregues a ela $(f(1) = 1, f(2) = 4, f(3) = 9, \ldots)$. Por exemplo, $f(x) = \sin(2\pi x)+x^2$.
Aí entra o primeiro objeto de ML: a Classe de Hipóteses ($\mathcal{H}$). Uma “hipótese” é uma possível função geradora dos dados. A ideia é que entrará no conjunto da classe de hipóteses apenas funções que eu jugo aceitáveis. Por exemplo, eu poderia dizer que $\mathcal{H}$ é o conjunto de todos os polinômios. Nesse caso, $f(x) = x^2$ estaria em $\mathcal{H}$, mas $f(x) = \sin(2\pi x)+x^2$ não estaria.
O problema é que nem sempre a classe de hipóteses conterá a função que gera os dados. Pode ser que meus dados tenham um ruído, o que é comum em qualquer coisa que envolva a vida real:
| 1 | 1.01 |
| 2 | 4.16 |
| 3 | 8.94 |
| 4 | 16.22 |
Talvez exista uma classe de hipóteses que contenha exatamente exatamente a função que descreve todas as leis físicas e quânticas responsáveis pela minha medida não ter saído exatamente 16, mas sim 16.22.
Mas mesmo que isso me desse uma hipótese mais precisa, é justo afirmar que nós vamos querer trabalhar com funções simples, afinal, eu não tenho os dados nem a computação necessária para simular isso. Por isso, eu faço a escolha de usar uma classe de hipóteses mais simples, como o conjunto de todos os polinômios de grau $\leq 3$.
O problema é que agora nenhum polinômio vai resultar exatamente no meu conjunto de dados. Por isso, entra agora o segundo objeto fundamental de ML: a Função de Erro (ou Função de Perda) $E$.
A função de erro recebe uma hipótese e diz quão errada ela está baseada nos meus dados. Por exemplo, se eu jogasse a hipótese $f(x) = 4x$ ela deveria retornar um erro maior que a hipótese $f(x) = x^2$.
Dentro de uma classe de hipóteses nós escolheremos a hipótese de menor erro.
No caso específico que eu estou falando, normalmente se usa o erro quadrático médio. É basicamente a média do quadrado da diferença entre o valor previsto pela hipótese ($y_h$) e valor experimental ($y_d$) (os dados): $E = \frac{1}{n} \sum (y_h-y_d)^2$. O motivo de usar esse erro tem motivações estatísticas (no caso, ela é a função de erro que surge supondo que o ruído é normalmente distribuído).
Mas, assim como a escolha de classe de hipóteses, a escolha de função de erro também é “subjetiva”. A escolha de ambos depende de algum conhecimento prévio sobre os dados apresentados.
Tipos de aprendizado supervisionado
O motivo de eu ter falado todos esses termos técnicos é que a escolha de $\mathcal{H}$ e $E$, e o conjunto de dados determinam nosso aprendizado:
Regressão
Aqui, entrada e saída são tipicamente números. É novamente o caso apresentado na introdução, você recebe um número $x$ e a saída $x^2$. Portanto, normalmente existem infinitas possíveis saídas.
As aplicações principais são na ciência. Por exemplo, você poderia analisar a relação entre compressão de mola e força de resposta, e perceberia que existe uma relação aproximadamente quadrática. Ou talvez você seja um businessperson e queira saber a relação entre área e preço de uma casa, e verá que ela é linear:
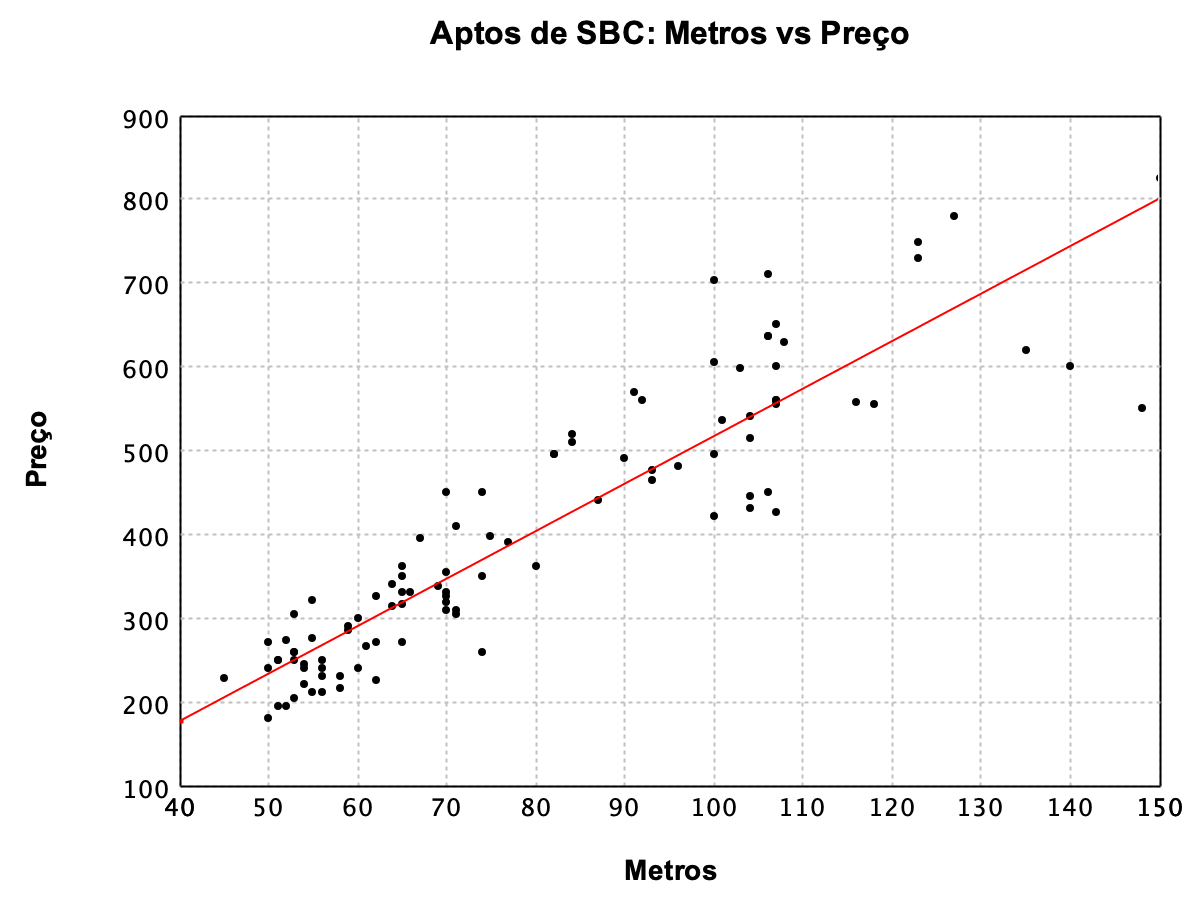 (imagem obtida em https://www.sakurai.dev.br/regressao-linear-simples/)
(imagem obtida em https://www.sakurai.dev.br/regressao-linear-simples/)
Classificação
Diferente da regressão, a saída é uma categoria, e portanto, finitas saídas possíveis. Talvez a entrada seja sua altura e peso, e as categorias são “abaixo do peso”, “normal”, “sobrepeso”, “obeso” e “obesidade mórbida”:
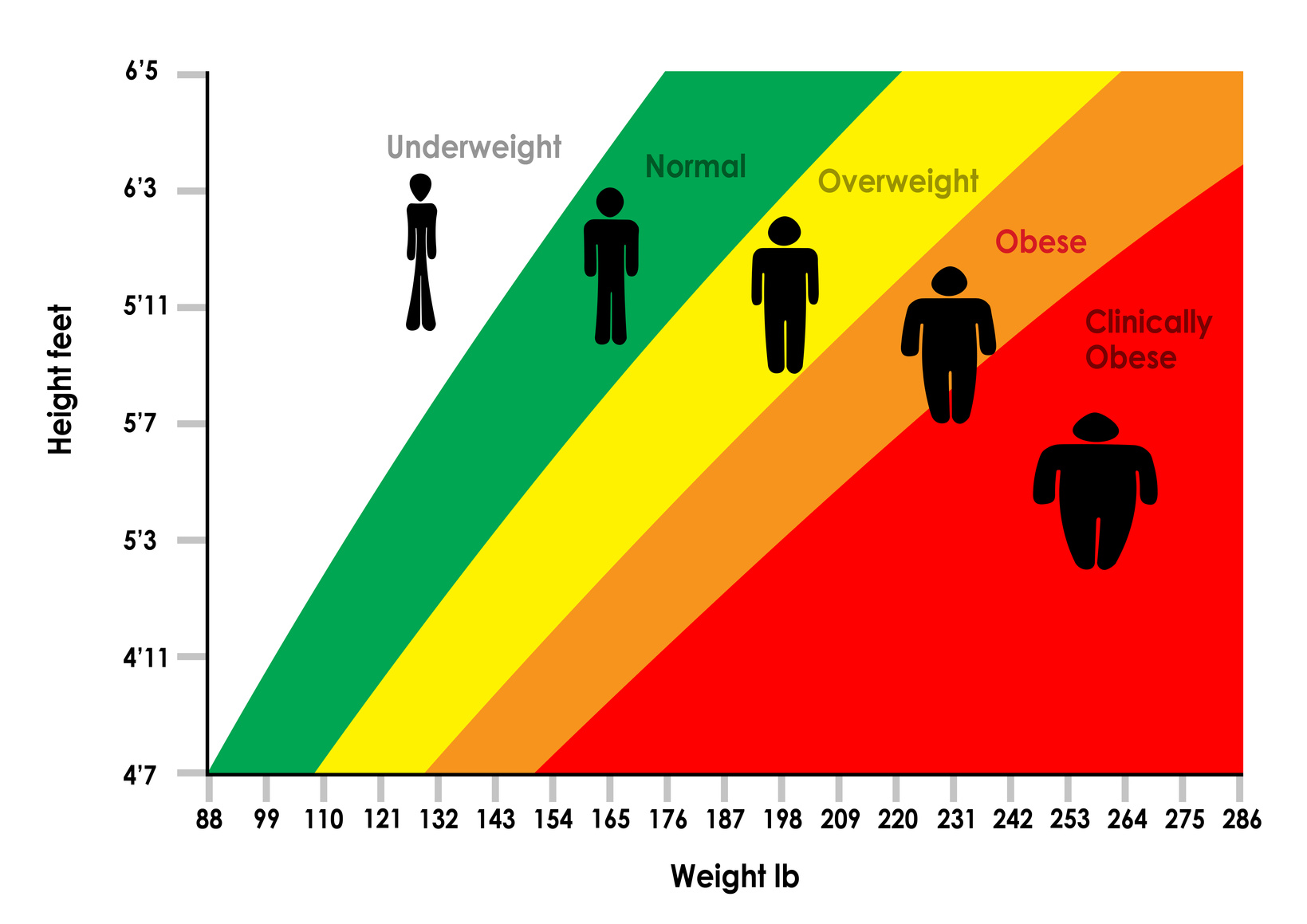
E é na classificação que entram as aplicações mais divertidas. É só que normalmente é difícil de perceber como algumas técnicas de aprendizado de máquina são no fundo um problema de classificação:
-
Reconhecimento de áudio: A entrada é o áudio (um monte de números correspondentes às frequências e períodos) e ele é classificado dentre alguns fonemas, depois em palavras, e por fim numa frase.
-
Reconhecimento de imagens: A imagem é um monte de números correspondentes a cor de cada pixel, a saída é alguma categoria como “é um rosto”, ou “é o rosto do Mark Zuckerberg” ou “é um pato de borracha”.
-
ChatGPT: Esse caso deve ser o menos óbvio. O ChatGPT funciona de forma iterativa: ele escreve a resposta prevendo a próxima palavra mais provável. A maneira que isso é feito é classificando as palavras anteriores, e a “categoria” é a próxima palavra. Então: $f($“eu gosto”$)$ = “de”, e depois: $f($“eu gosto de”$)$ = “pizza”.
-
De fato, todo modelo generativo envolve um problema de classificação. Mas isso é fora do meu escopo.
Mas e as redes neurais???
Todos gostamos de redes neurais. Elas criam uma classe de hipótese composta de “cérebros” que possuem camadas de “neurônios”. Cada neurônio de uma camada se conecta com neurônios da próxima camada usando “axônios”. Matematicamente, os neuronios armazenam números, e os axônios combinam os números dos neurônios anteriores e armazenam no próximo.
O motivo delas serem tão famosas e úteis é que elas são o que os cientistas chamam de aproximadora universal. Elas conseguem modelar qualquer $f$ que você for precisar, você não precisa se preocupar em saber se o seu dataset é polinomial, ou exponencial, ou que seja.
Mas tem um custo: elas precisam de muito trabalho para funcionar. No caso, um dataset gigantesco e muito tempo de processamento. O GPT-4 por exemplo, possui em torno de um trilhão de parâmetros.
Modelos que ninguém que liga
Além de redes neurais, existem outros tipos de modelos muito importantes para você aprender. É claro, elas não vão te deixar molhado como as “redes neurais” deixam, e muitas vezes você vai só usar modelos lineares mesmo porque são mais fáceis, mas se você souber o que está fazendo de verdade eles são importantes:
- Modelos lineares gerais (engloba muitas coisas)
- Support Vector Machine (SVM)
- $k$-nearest neighbors (kNN)
- pergunta pro chatGPT
Cada um desses possuem aplicações tanto a regressão quanto a classificação, e cabe a você, cientista, determinar o melhor para seu papel. Os métodos de modelar a função são diversos, desde funções simples, até funções baseadas em árvores, grafos, e muita estatística.
Tipos de aprendizado não-supervisionado
Eu falei até agora de problemas de aprendizado supervisionado. Isso significa que existe uma entrada e uma saída esperada dessa entrada. Mas é comum querermos aprender informação de um dado, sem necessariamente saber quais são as “saídas”.
Esse tipo de aprendizado é chamado de não-supervisionado, e existem vários tipos de coisas que podemos aprender sobre um dataset:
Clustering
Um exemplo científico disso: suponhamos que você está coletando informações de uma espécie de passáros. Assim como cachorros, esses pássaros possuem várias “raças”. Todavia, você não sabe quantas raças existem, nem o que afeta elas.
Para esse tipo de problema, existe o Clustering. Em termos simples, o clustering pega todos os pontos do seu dataset (por exemplo, um ponto seria um pássaro, e as coordenadas desse ponto seriam medidas dele, como peso, altura, etc.). Naturalmente, pássaros da mesma raça terão atributos físicos semelhantes, e ficaram próximos um do outro de alguma forma.
É isso que algoritmos de clustering fazem. A máquina aprende informações de grupos, e inclusive isso pode ser usado posteriomente em um aprendizado supervisionado de classificação.
Existem vários algoritmos, como K-means, DBSCAN, etc. Eles são divididos em seus princípios de funcionamento, por exemplo, o DBSCAN é baseado na densidade de pontos, o K-means é baseado em encontrar “centroides” de um grupo, e por aí vaí.
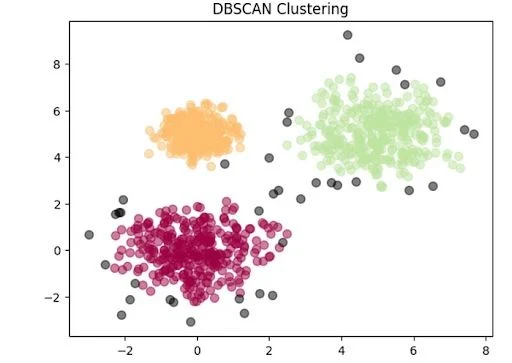
Dimensionality reduction
Outra informação que podemos aprender em um dataset é extrair apenas os dados que são estatisticamente relevantes. Por exemplo, não é incomum que dois dados sejam correlacionados entre si (e somente entre si). Podemos inferir então que é como se esses dois dados na verdade viessem de apenas um só.
A redução de dimensionalidade existe justamente para transformar os dados em novos variáveis que sejam o menos correlacionadas o possível. O principal algoritmo disso é o PCA (Principal component analysis).
O objetivo disso é diminuir a quantidade de dados que você precisa processar, o que é fundamental na aplicação de algoritmos mais complexos de aprendizado de máquina.

Enfim, existem vários problemas que o aprendizado não-supervisionado, geralmente são úteis na análise de dados.
Reinforcement Learning
Por fim, o Reinforcement learning (RL). Ele é diferente dos dois no sentido que não depende de uma “saída esperada”. Você também não tem um ‘dataset’ que você vai extrair informação.
No RL, seu dataset é dinâmico e desconhecido. Ele depende da sua “função”. Um robô, por exemplo: o que ele vê (os dados que alimentam suas ações) dependem das próprias ações do robô (o que é a função que descreve p comportamento dele).
Você não está mais tentando “imitar” o ambiente, mas sim o que eu instruí. Isso é feito através de um sistema de recompensas, bem parecido com como você ensina animais. Se eu quero que minha máquina adquira um certo comportamente, eu vou fazer com que ela ganhe recompensas quando faz algo que eu quero, e logo a função vencedora será a que maximizar a recompensa.
Por exemplo, eu poderia treinar um robô para seguir pessoas. Quanto mais próximo de uma pessoa, maior a recompensa, então a função que maximiza a recompensa é a que melhor segue as pessoas.
Esse o mais divertido talvez, porque esses modelos se adaptam ao ambiente. Você não precisa saber como funciona exatamente o ambiente, apenas saber o que você quer que a máquina faça. Assim, eu não preciso gastar horas pensando emm como é a melhor forma de fazer meu robô andar, estudar a mecânica de robôs em solos complexos, ele próprio vai aprender isso tentando maximizar a recompensa.
É assim que funcionam os algoritmos que te prendem no tiktok: a recompensa do algoritmo é o tempo que você gasta no app, e ele vai descobrir qual a melhor forma de recomendar vídeos de forma que maximize o tempo que você fica no celular. Sim, é nisso que a ciência está gastando seus esforços, não minizar a fome e bem estar da população.